
Notes on Europython 2020
Data
From July 23 to July 26, I attended Europython 2020 online. Here, I will go over my notes.
Disclaimer: I've attended some talks that I've not included here. Since there were at all times 4 tracks running in parallel, I could not attend 75% of the talks. For these 2 reasons, these notes reflect my personal Europython experience.
Typing
Python is dynamically typed and can be statically typed.
mypy originated out of Dropbox (Jukka Lehtosalo) as a tool to statically check python code.
One key design decision was made when Guido van Rossum (the former BDFL
of Python) nudged Jukka Lehtosalo to drop using a typing DSL and instead rely on type hints,
which are now common for python 3.6+ . There are other static type checkers like pytype (Google) which has improvements over mypy.
Static type checking gives free advantages (IDE completion, documentation, error catching).
The gist of this talk is that even if you enforce types in your python backend code, it's not enough because your stack is made of more than python.
SQL is stricter than python which is stricter than JS.
A type safety stack might look like this:
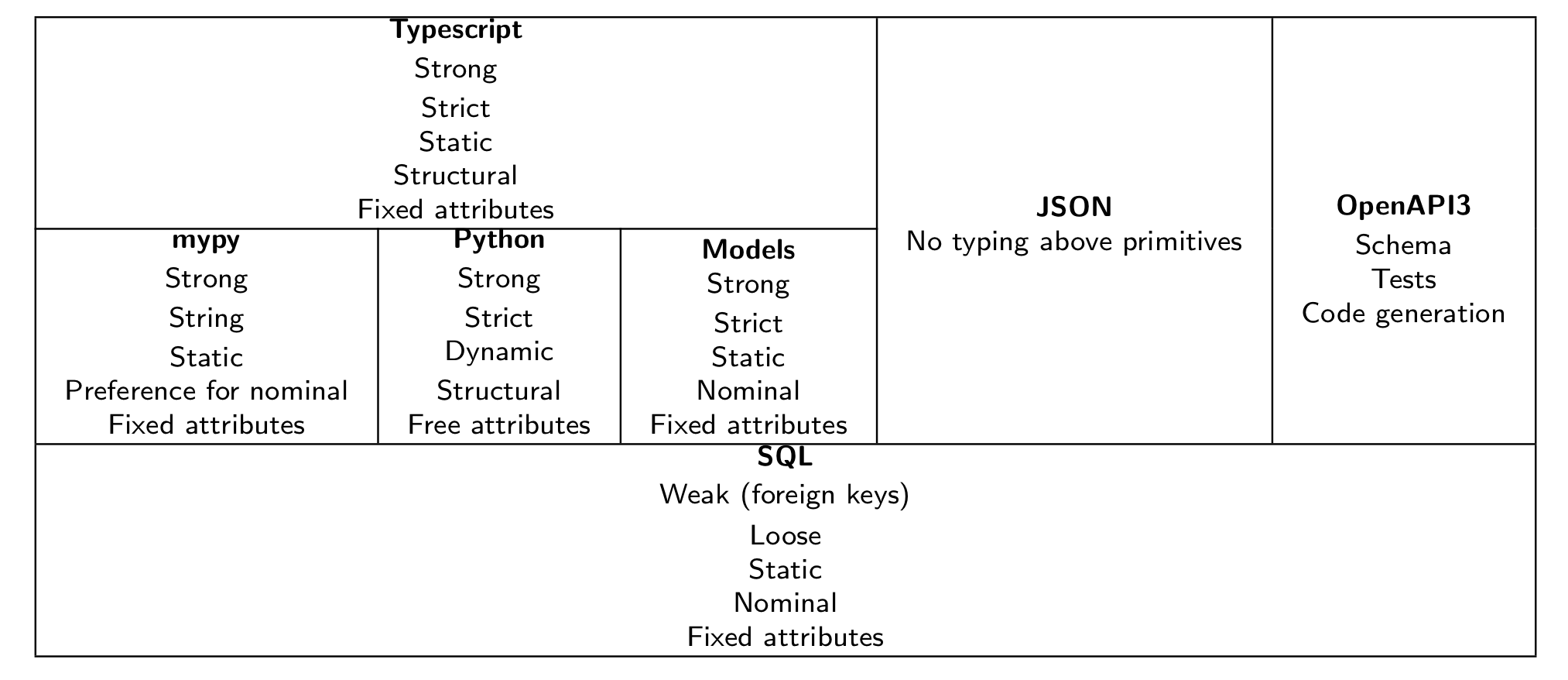 With a tool like
With a tool like pydantic, you can marshall incoming JSON, and can annotate your python code with more complex data types. You can statically check your code with mypy.
With tools like fastAPI (based on pydantic) or strawberry-graphql you can generate OpenAPI specifications straight from the type annotations.
With tools like openapi-generator you can generate TypeScript classes from an OpenApi spec.
Serge Sans Paille leads a community of pythonistas that are hard at work to make static python analysis suck less.
This artform relies on parsing Abstract Syntax Trees (ASTs) reliably (eg: what your linter does).
To that effect, he provides multiple tools like gast (which has 160k downloads per day !), beniget or memestra.
This tools was definitely above my level but showed that even if python is not meant for static analysis, you can still create great tooling for it.
Python best practices gotchas
Combining Object Oriented Programming (OOP) and Functional Programming (FP) is powerful, if done right.
One gotcha was to use toolz.functoolz.thread_last
to make code readable from left to right. It takes more time to write but is easier to read, as this quote puts it:
“I would have written a shorter letter, but I did not have the time.” ― Blaise Pascal
raw_example = "7055862"
# bad
values = []
for digit in raw_example:
values.append(int(digit))
# better
values = tuple(map(int, raw_example))
# good
from toolz.functoolz import thread_last
values = thread_last(raw_example, (map, int), tuple)
# or
values = [int(digit) for digit in raw_example]
Another gotcha was to define idempotent FP functions outside classes and use them inside.
Zen of python is great. One gotcha was to use the cartesian product instead of nested for loops:
# bad
alpha = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
for r in ('WK'):
for l1 in alpha:
for l2 in alpha:
for l3 in alpha:
print(f"{r}{l1}{l2}{l3}")
# good
import itertools
alpha = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
for r, l1, l2, l3 in itertools.product('WK', alpha, alpha, alpha):
print(f"{r}{l1}{l2}{l3}")
NLP
The intuition behind self-attention is that it's a re-weighting mechanism on top of pre-computed word vectors, that account for the fact that language is a sequence. Bank has a different meaning in the sequence "money in the bank" than in the sequence "the bank of the river". The simplest attention mechanism you can design is by doing a dot product of the word embeddings, normalise them and add them up to get a context-sensitive embedding.

You can move this idea into a layer, which gets you a so-called Self-Attention Block which turns a sequence of word embeddings into context-sensitive embeddings. It's all fine but at this point you are not learning anything because there are no weights to tune. It's when you add those extra layers of learnable weights to the self-attention block that you get a Transformer Layer.
The speaker then goes into how Rasa applies the transformer idea to their business problem of dialogue systems. He mentions DIET (Dual Intent and Entity Transformer) which is their way to label entities and classify intents both at the same time (the really cool part is the shared gradient update). He also mentions TED (Transformer Embedding Dialog) which is they way to decide what action to take for the chatbot. The really cool part there is that you don't have to use word embeddings to use transformers: TED is not even using text data but instead, it's using a composite feature space.
The idea of this talk is that instead of using an external enigne like ElasicSearch (based on Apache Lucene), you can use native PostgreSQL's Full text search feature. Because this can be too low-level, the speaker advises to use a web-framework. His choice is on Django, which has great support for fulltext-search. See django.contrib.postgres.search.
The speaker presents his library that wraps around spacy, elasticsearch and the python docker client to build an end to end NLP pipeline. This is an interesting workflow for ad-hoc analysis or for small projects where you don't need APIs between ElasticSearch, a stream of article and a language model. Example python notebooks can be found here.
Data
I had seen this talk before. Don't connect to kafak streams with anything other than faust.
The modelling potential of graph databases in inherently bigger than relational DBs. TerminusDB is positioned
at the top of the foodchain. It shines especially to build ontologies or knowledge graphs.
The python client is in the making but tries to be very pythonic.
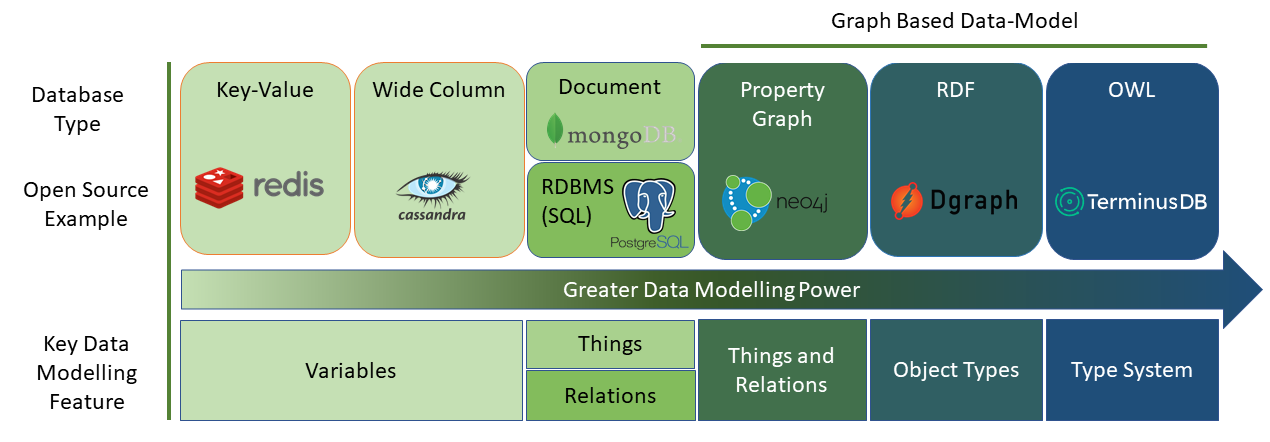 More details here.
More details here.
Really advanced talk about ScyllaDB (used by Discord for example).
ScyllaDB add a key feature on top of Cassandra which is to shard data by CPU on a node (shard-per-core)
instead of "just" by node in a cluster (shard-per-node).
For both Cassandra and Scylla, when looking for a data row, you can locate the shard where it's stored by
hashing its partition key, which gives you a token.
For ScyllaDB, this means that you know which CPU will crunch that row so you can optimise the query plan.
If your client implements this, you can preselect the right node to query in the python cassandra driver,
and hence you save network, and get reduced latency (due to naïvely querying the cluster and then letting the
clustering sort out where the data is).
You also get reduced load on the cluster which means you can achieve the same thorughput with a smaller cluster.
First advice to make pandas faster is to save RAM to fit more data. For example, cast raw strings as pandas categoricals.
If you encode low cardinality items well, you can get 1% memory footprint for 15x speed up.
He introduced his tool dtype_diet to automatically shrink your pandas footprint.
Second advice was about dropping to numpy to calculate faster. Some pandas types are not part of numpy (like timedeltas, datetimes etc...). But you can get a 10x speedup.
Pandas has 2 recommended dependencies
bottleneck and numexpr that will give you another speedup as well.
Finally, you can wrap your slow function with @njit from numba but not everything is supported.
Or you could scale out of core by using dask.
Ultimately the takeaway was that you should worry about being performant (writing unit tests, writing time saving docs, ...)
Get things right first, and worry about speed later
Ref: Enhancing performance — pandas 1.0.5 documentation
Web and APIs
This talks introduced property based testing (PBT) as a great way to surface a spectrum
of defects inherent to any application.
For example, making sure the schema you hand in to clients is valid;
or finding simple unhandled errors or more severe logic errors that
arise from corner cases not unit tested for.
In practice, it means you're going to catch some errors in dev
before your error tracking tool (e.g. Sentry) reports them to you in stg or prod.
hypothesis is a powerful, flexible, and easy to use library
for doing property-based testing in python.
schemathesis is a tool built on top of schemathesis that generates
and runs test cases from an OpenAPI specification.
Based on the QuickREST Paper, 20 Dec 2019.
If you have a python application, you can integrate schemathesis to your pytest test suite.
If you don't have a python app, you can run schemathesis over HTTP as long as you can point it to the OpenAPI spec.
The hypercorn (ASGI server) creator talked us through the new standard ASGI (as opposed to WSGI).
The main advantages are that the new standard enables asynchronous execution.
"Asynchronous" refers to concurrent IO-bound code suing async/await syntax enabled by the asyncio library
(example of IO-bound: HTTP requests; example of CPU-bound: compression).
Another advantage is that you can swap out your ASGI server for another (e.g. uvicorn for hypercorn).
In order to write an ASGI server, you need to translate HTTP messages to ASGI and back.
After the web server from the previous talk, this talk is about asynchronous web framework alternatives to flask.
Although Flask revolutionised webdev in python, it is synchronous; meaning it can be 3 to 4 times slower than asynchronous alternatives.
The talk introduces sanic a webframework very similar to Flask in its API but written with asyncio.
The speaker shows how easy it is to convert a flask API to sanic due to how close the APIs were designed to be.
Sanic can be an alternative to FastAPI although FastAPI does not just offer async, but also
offers typing based data validation, and puts dependency injection as a guiding principle.
The speaker explains that you should benchmark your own use cases with real data and not trust "fake" speed benchmarks.
The goal being to figure out where are the bottlenecks of your application and how to improve them.
His toolbox for benchmarking is ab (Apache Bench), pytest-benchmark sometimes, cProfile, snakeviz,
Prometheus & Grafana(to get insights on how physical resources are used when deployed to k8s), blazemeter.
Macro Trends
With HTTP/1.1, you can have 6 connections per domain. This means that clients use a connection pool
to download 6 objects at the same time.
If there are more objects to download, they are queued like in a traffic jam.
With HTTP/2, multiplexing was introduced which meant that you could download
multiple objects through 1 connection; while also being limited to 1 connection per domain.
It was designed to speed up latency: you bundle things and don’t need to wait for many connections.
HTTP transfers data over TCP.
TCP is a protocol layer that handles network unreliabilities for you.
You can write anything to a TCP socket (email POP3, or FTP, or HTTP).
TCP is also responsible of the head-of-line blocking (the traffic jam).
There is a TCP alternative called QUIC that comes out of Google.
It gives you a reliable bytestream like TCP.
But it has TLC built-in which means it is encrypted by default.
It also improves performance by leveraging independent bytes streams, thus avouding head-of-line blocking.
HTTP/3 is HTTP, rebuilt on top of QUIC instead of TCP. It can change the Internet as we know it today.
More time is needed for HTTP/3 to come out of Google and be standardized by IETF, let alone be supported by python libraries likes httpx.
Just like you would extend python code with C for improving speed, you can also extend python with Rust. Essentially you turn your Rust code into a dynamic library (.dll file on Windows, .so on Linux, or .dylib on Mac) using a python wrappers like maturin. You can build the dynamic library with a docker multi-stage build for example. You can upload it to PyPI (or a private pip server).
In order to achieve privacy-preserving machine learning, you can add noise to your training data (concept of "bounds"). There is the idea of fixing a privacy budget for a dataset, and then spending it on training your pipeline (concept of "epsilon").